Day 30 of the Data Engineering Zoomcamp Cohort 2025 course and how has it been 30 DAYS! Wow does time fly. I am so proud of all of us who have been consistent with this course. Alexey wasn’t wrong in stating that the first two weeks with docker were tough! It feels a lot smoother lately.
In module 3 we learned more about BigQuery and did you know you can play around with things in a sandbox here! My favorite section of this week was talking about Partitioning and Clustering! This image explains it pretty well, where we are just organizing the data by ‘partitioning’ it and then in this case, by also clustering it by tags.
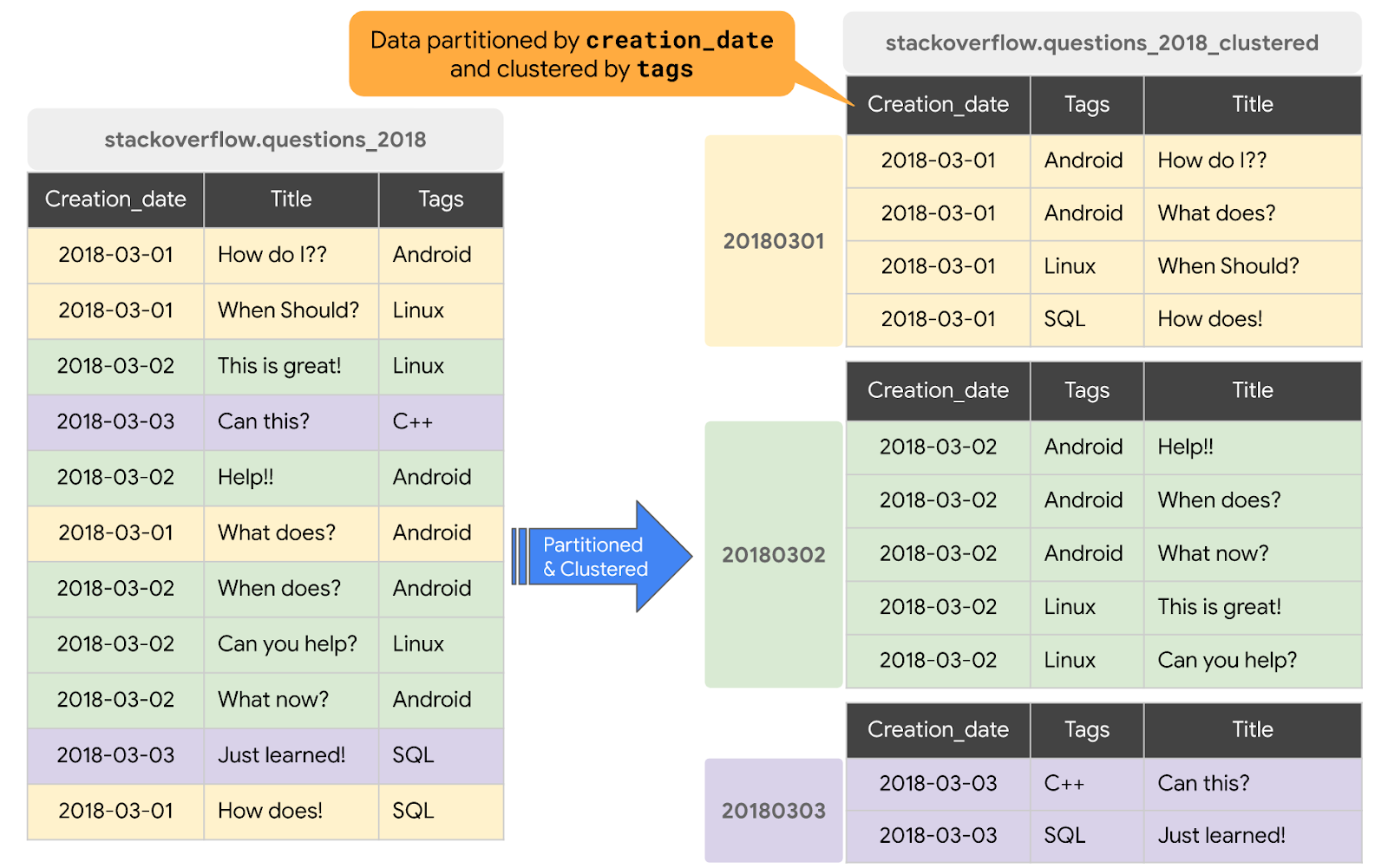
You can cluster for up to 4 fields! Also, you will likely only want to do partitioning and clustering if data size is larger than 1 GB, otherwise it may actually be more costly and won’t save time. BigQuery automatically reclusters the table as new data comes in.
Check out my Gitbook notes and homework solutions and feel free to leave me a note in issues or ask any questions!
Interested in joining the course?! I am writing this 2/11/25 and you can still join the Data Engineering Zoomcamp Cohort 2025 or if you’re late to reading this, the material should still live there. You can also follow along weekly, by checking the leaderboard to find homework submissions and links to github repos and #learninginpublic - my username is ‘Cloudy Bluewave’.